快速搭建ChatGPT
最近了解到高性能应用服务HAI,可以快速体验ChatGLM这款新型对话模型. 现在跟着我的节奏一起实现自己的gpt服务吧!
正文开始
- 申请高性能应用服务 HAI
- 点击链接进入高性能应用服务 HAI
- 申请体验资格
- 申请体验资格
- 等待审核通过后,进入高性能应用服务 HAI
- 点击新建
- 点击新建
- 选择配置
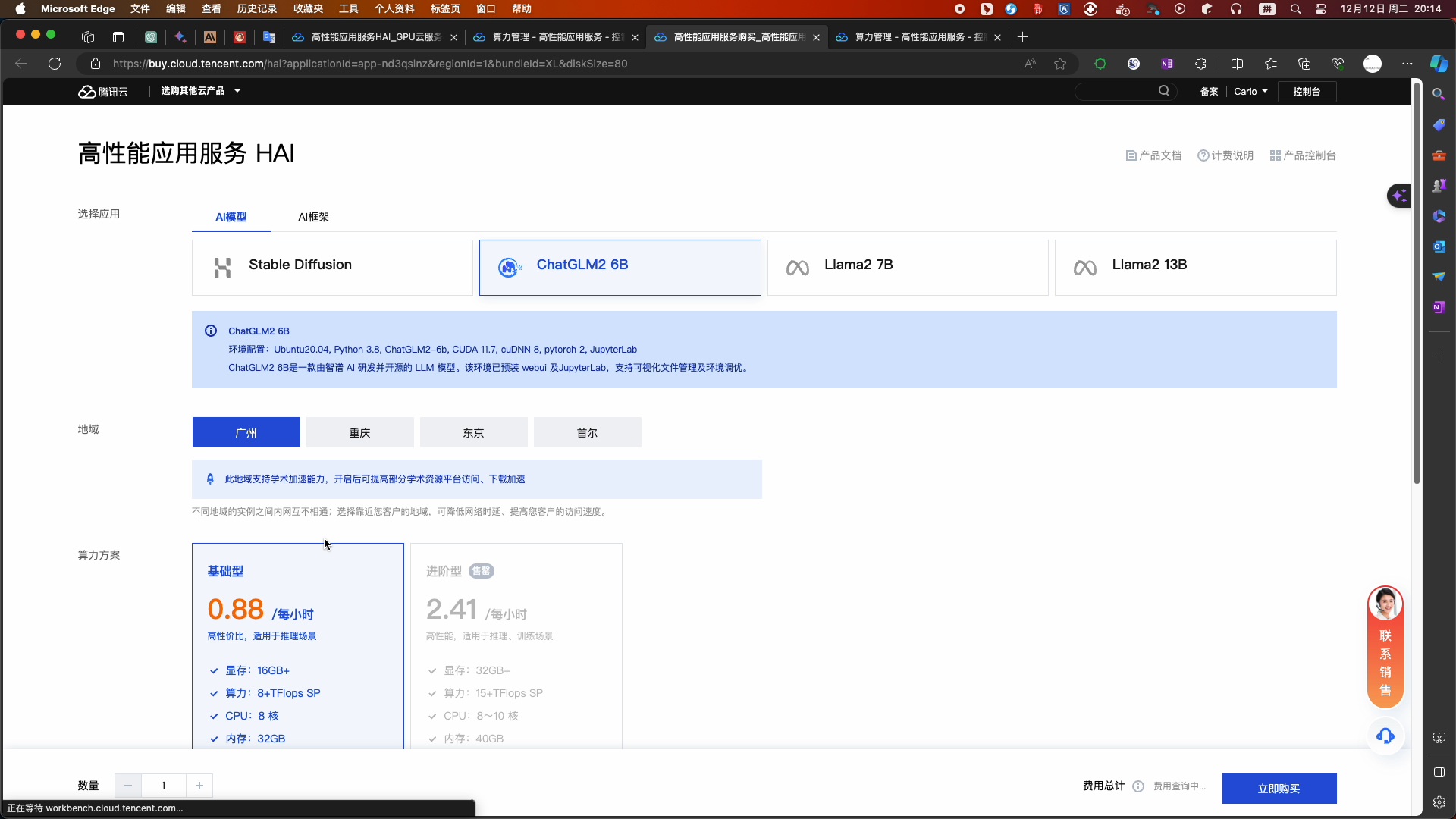
- 温馨提示:如果没有进阶型的算力方案(2.41元/小时),建议您购买基础型的算力方案(0.88元/小时),并在创建成功后参考实验过程中关闭 、重新开启 webui 功能的命令,以提高服务器的性能,加速您完成实验的体验!
- 等待创建完成(预计等待3-8分钟,等待时间不计费)
- 创建完成 查看相关状态
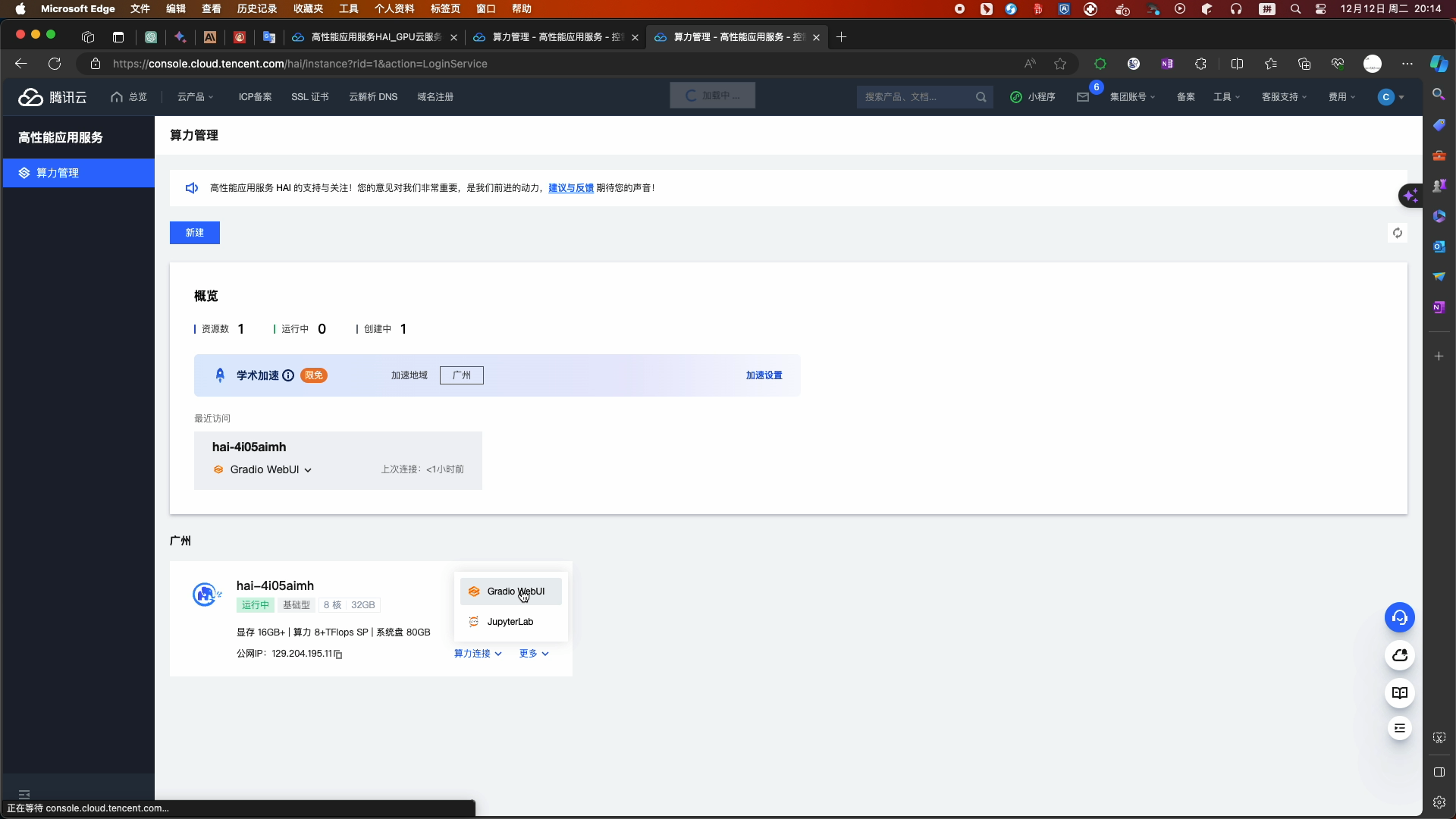
- 选择chatglm2_gradio进入WebUI页面
- 启动高性能应用服务HAI配置的ChatGLM2-6B WebUI进行简单的对话
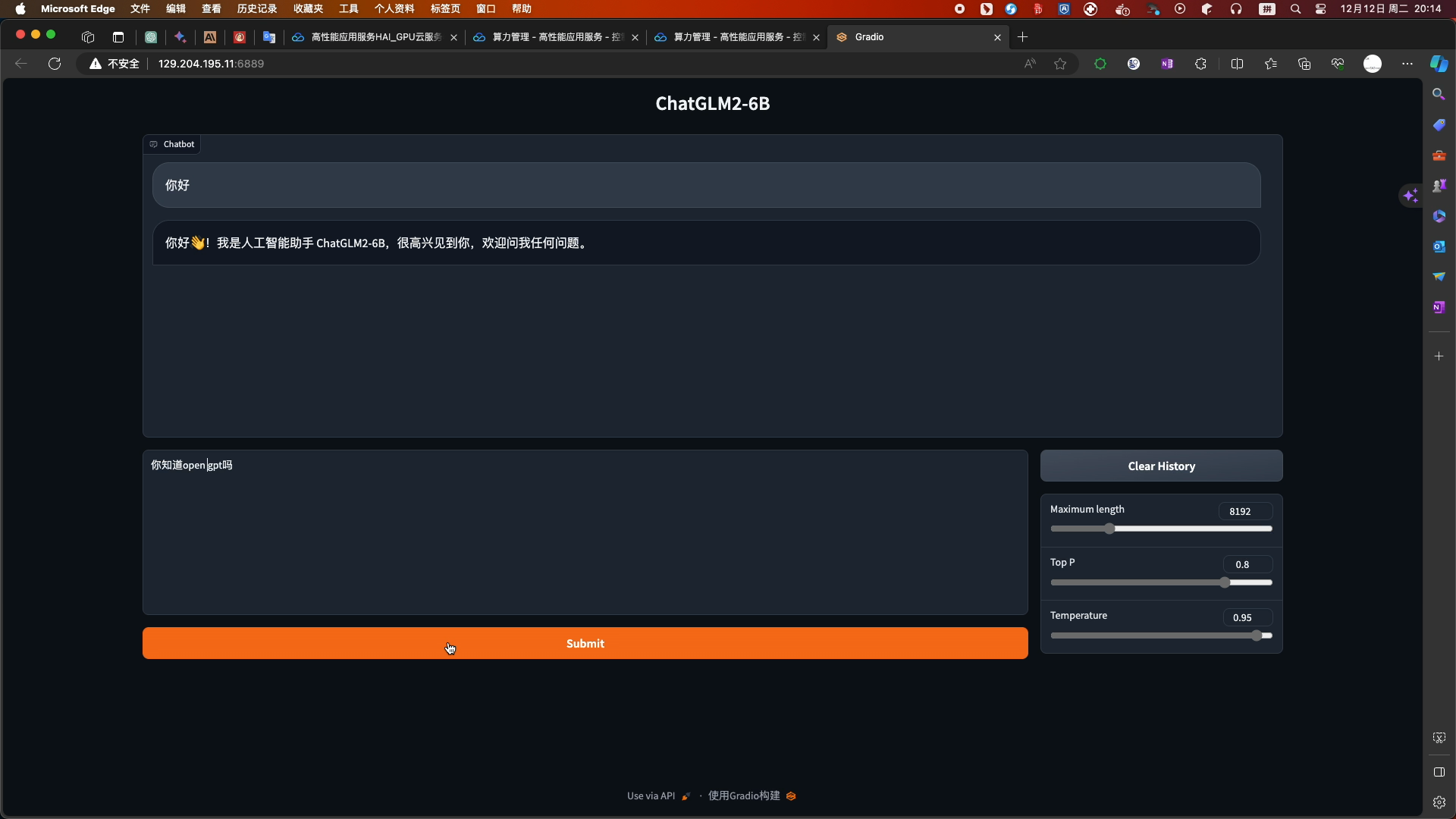
- 点击链接进入高性能应用服务 HAI
- 高性能应用服务HAI快速为开发者提供ChatGLM2-6B API服务
- 在算力管理页面,选择进入jupyter_lab页面
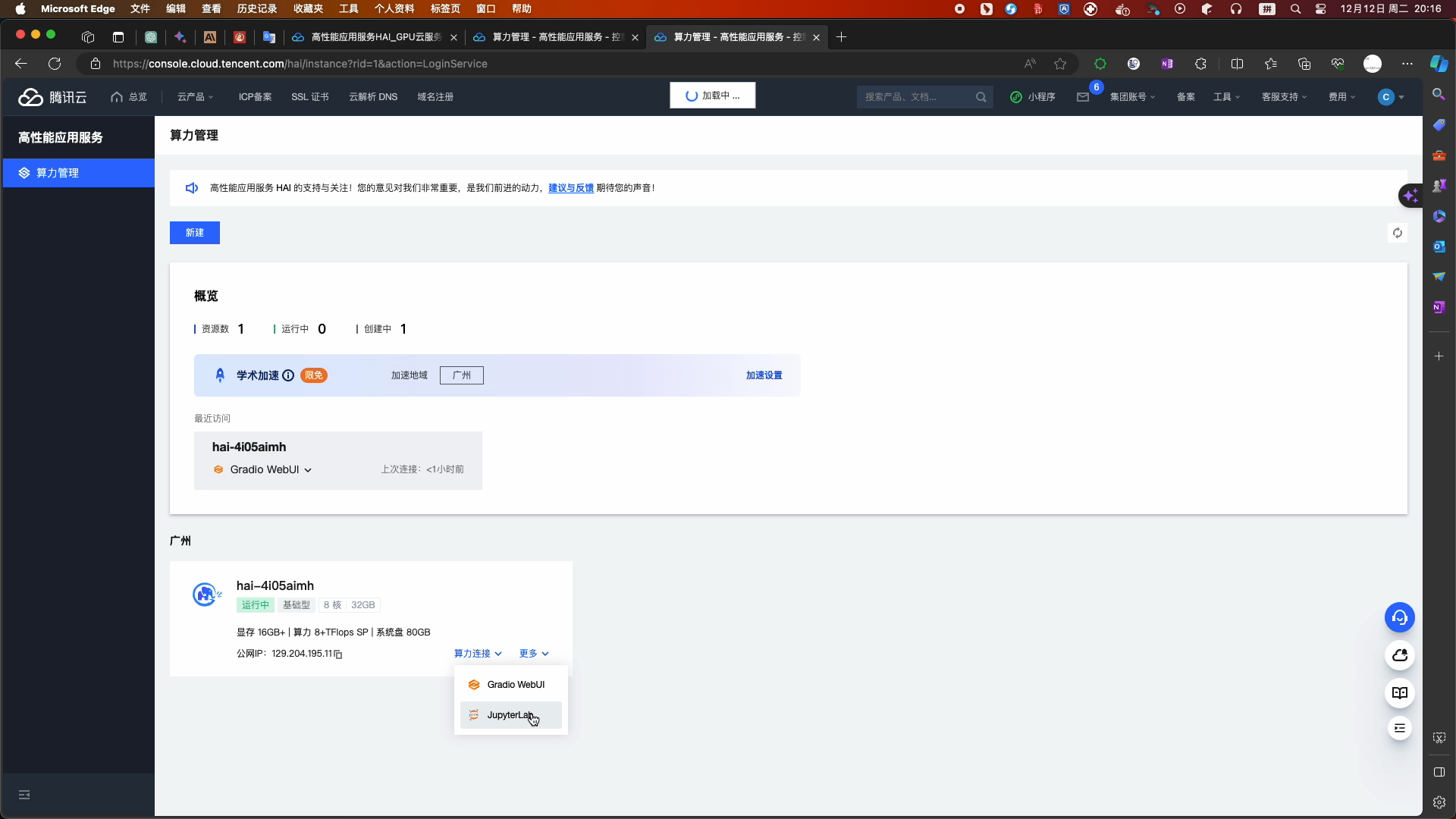
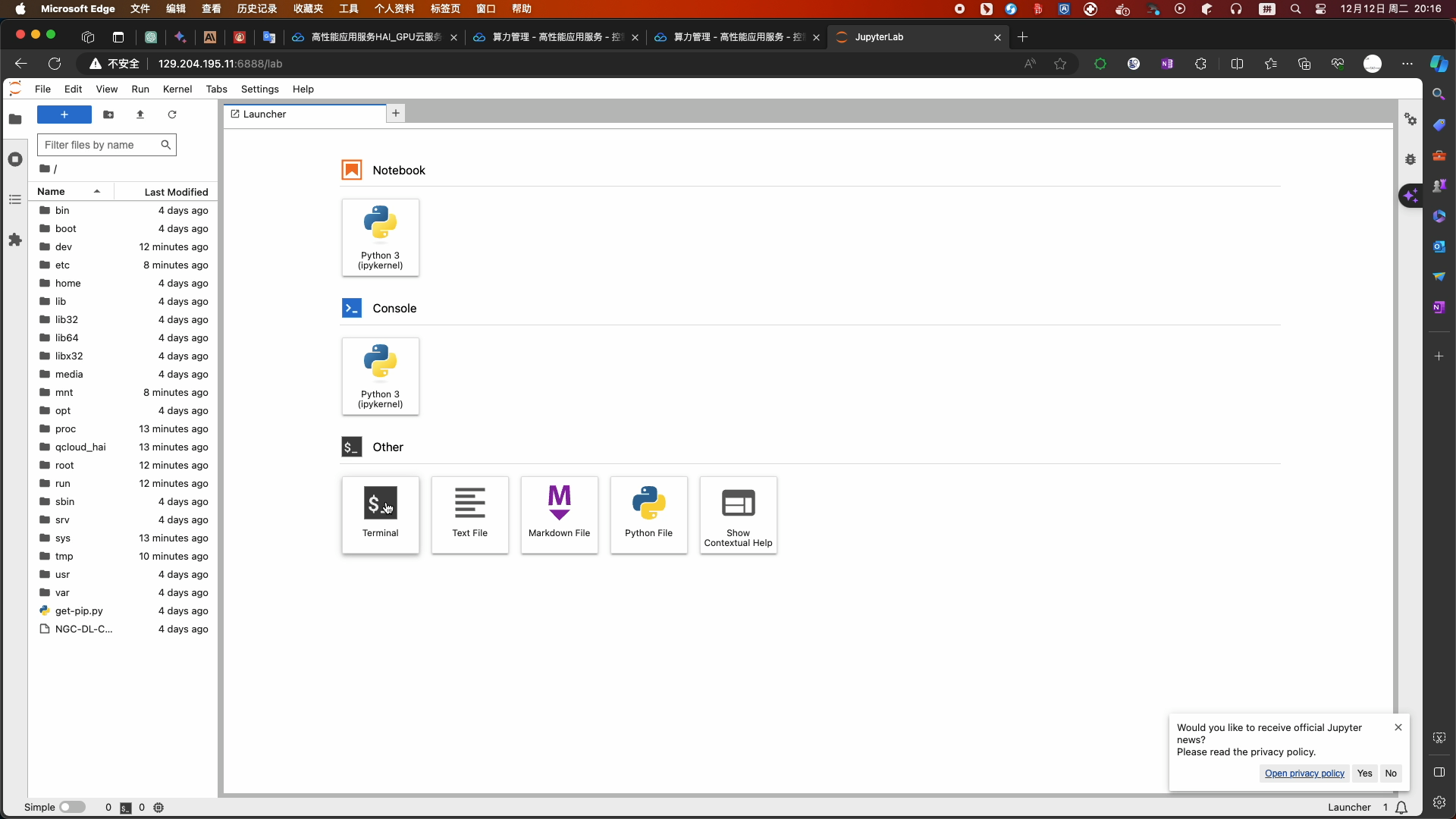
- 选择终端命令
- 温馨提示:如果您购买使用的是基础型算力服务器(0.88元/小时)请您在开始实验前输入以下关闭 webui 功能的命令,提高服务器的性能,以便后续实验能快速正常进行:
- 安装软件和关闭webui服务
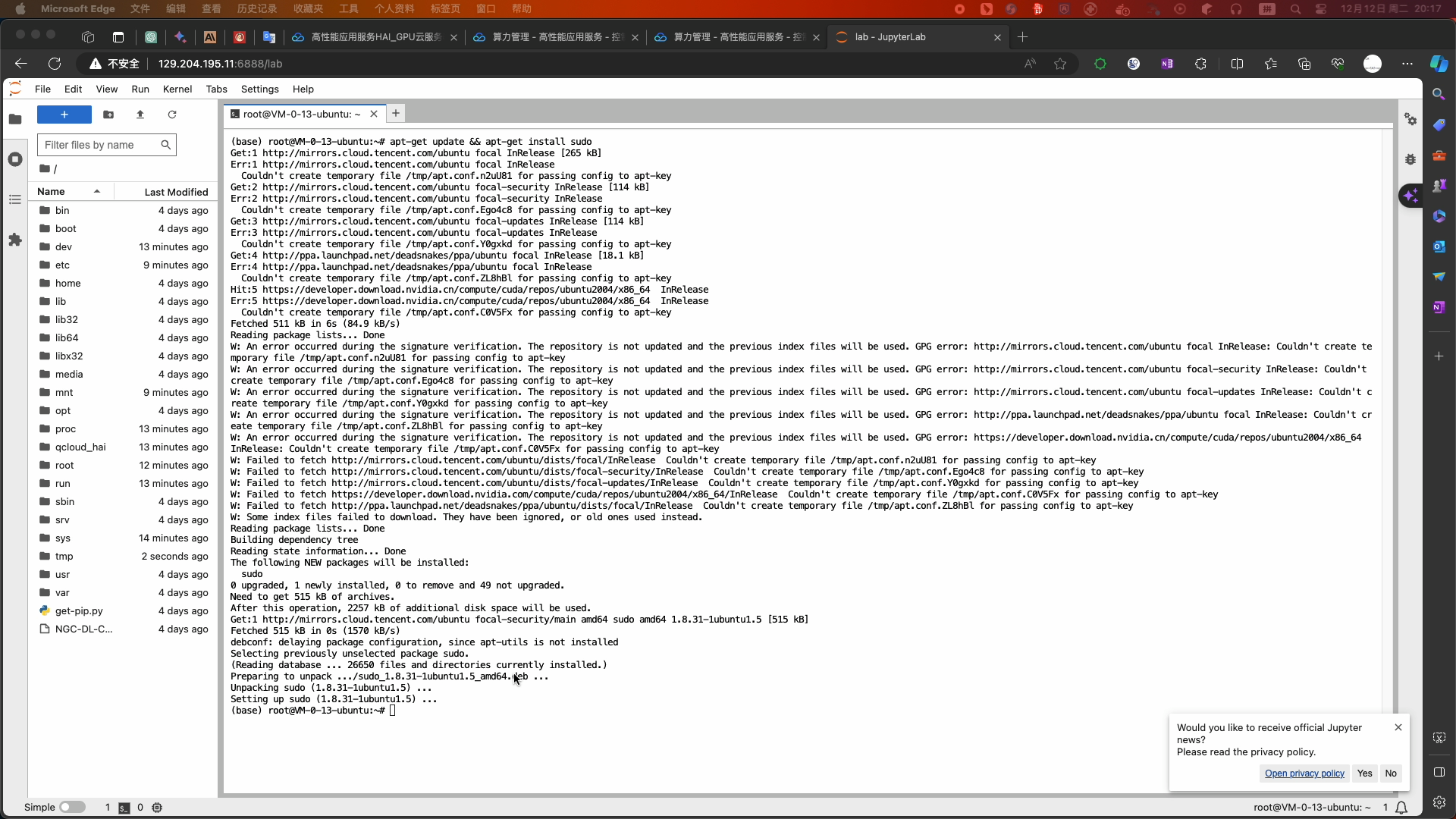
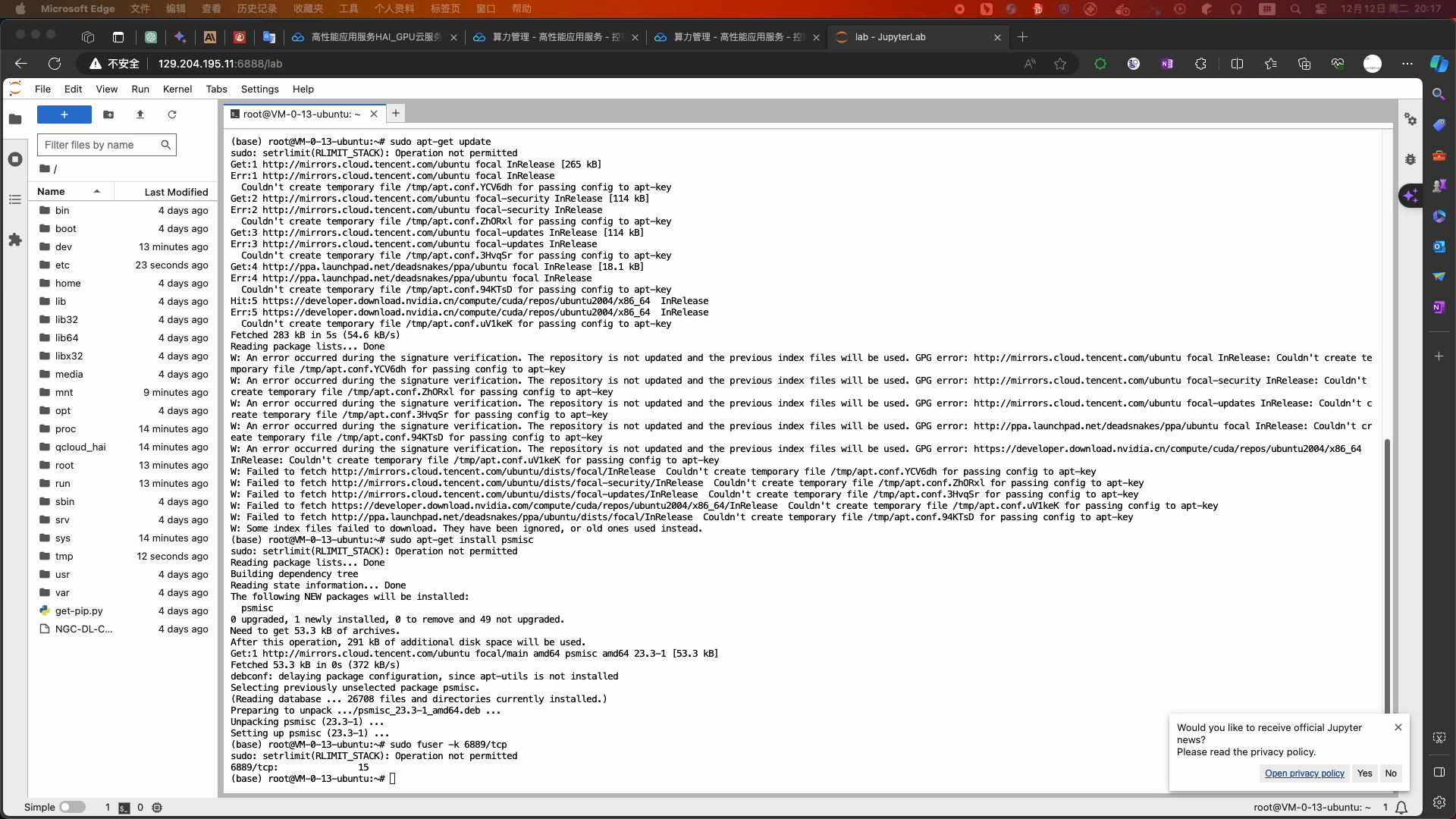
-
apt-get update && apt-get install sudo sudo apt-get update sudo apt-get install psmisc sudo fuser -k 6889/tcp #执行这条命令将关闭 HAI提供的 chatglm2_gradio webui功能 pip install aiohttp - 如果需要重新开启 webui 服务执行以下命令:
-
python /root/ChatGLM2-6B/web_demo.py --listen --port 6889 - 打开右边文件夹下的openai_api.py文件
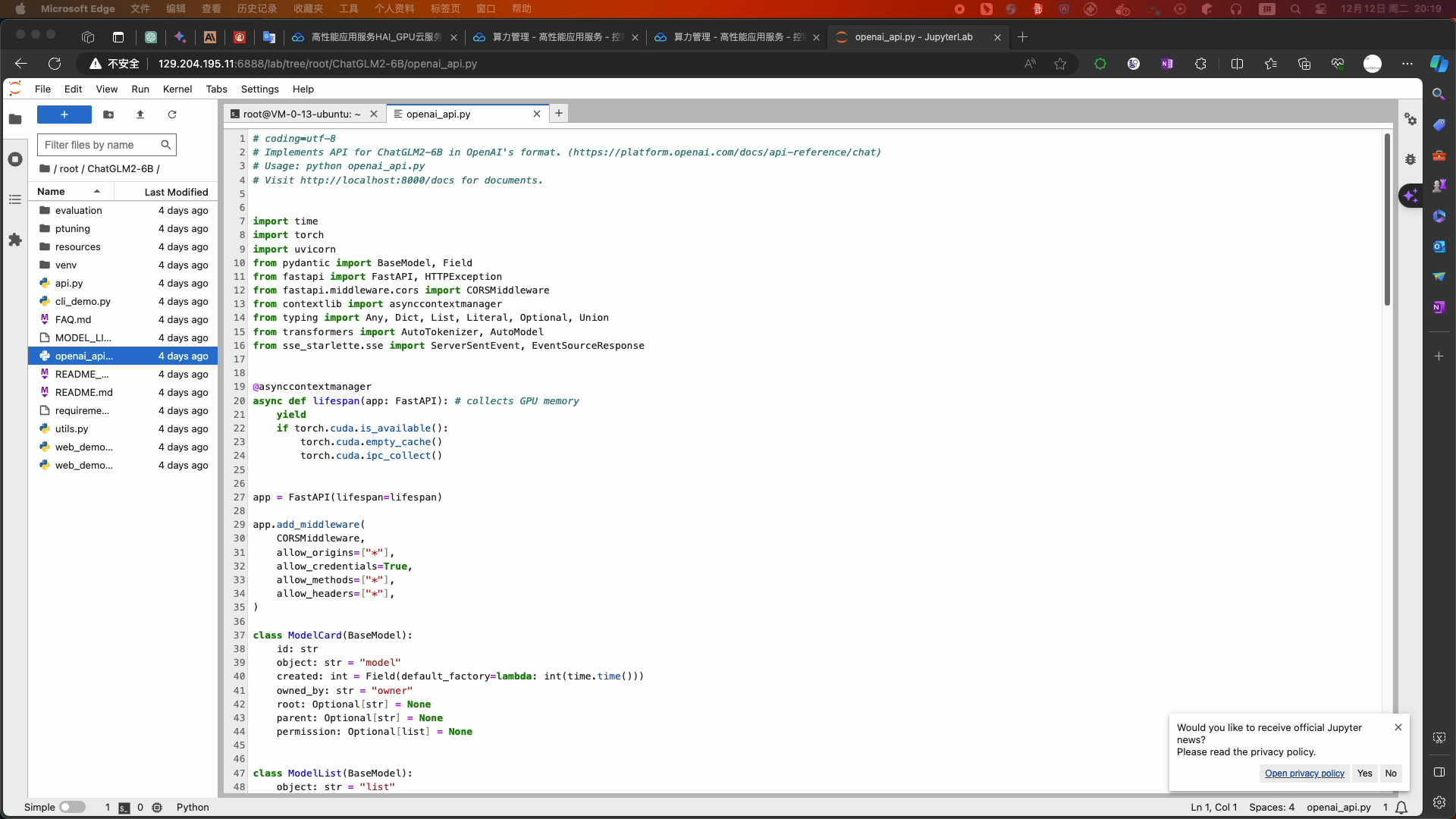
- 如果直接使用会在调用时报错,复制以下openai_api.py代码直接覆盖源文件并Ctrl+S保存代码
-
# coding=utf-8 # Implements API for ChatGLM2-6B in OpenAI's format. (https://platform.openai.com/docs/api-reference/chat) # Usage: python openai_api.py # Visit http://localhost:8000/docs for documents. import time import torch import uvicorn from pydantic import BaseModel, Field from fastapi import FastAPI, HTTPException from fastapi.middleware.cors import CORSMiddleware from contextlib import asynccontextmanager from typing import Any, Dict, List, Literal, Optional, Union from transformers import AutoTokenizer, AutoModel from sse_starlette.sse import ServerSentEvent, EventSourceResponse @asynccontextmanager async def lifespan(app: FastAPI): # collects GPU memory yield if torch.cuda.is_available(): torch.cuda.empty_cache() torch.cuda.ipc_collect() app = FastAPI(lifespan=lifespan) app.add_middleware( CORSMiddleware, allow_origins=["*"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"], ) class ModelCard(BaseModel): id: str object: str = "model" created: int = Field(default_factory=lambda: int(time.time())) owned_by: str = "owner" root: Optional[str] = None parent: Optional[str] = None permission: Optional[list] = None class ModelList(BaseModel): object: str = "list" data: List[ModelCard] = [] class ChatMessage(BaseModel): role: Literal["user", "assistant", "system"] content: str class DeltaMessage(BaseModel): role: Optional[Literal["user", "assistant", "system"]] = None content: Optional[str] = None class ChatCompletionRequest(BaseModel): model: str messages: List[ChatMessage] temperature: Optional[float] = None top_p: Optional[float] = None max_length: Optional[int] = None stream: Optional[bool] = False class ChatCompletionResponseChoice(BaseModel): index: int message: ChatMessage finish_reason: Literal["stop", "length"] class ChatCompletionResponseStreamChoice(BaseModel): index: int delta: DeltaMessage finish_reason: Optional[Literal["stop", "length"]] class ChatCompletionResponse(BaseModel): model: str object: Literal["chat.completion", "chat.completion.chunk"] choices: List[Union[ChatCompletionResponseChoice, ChatCompletionResponseStreamChoice]] created: Optional[int] = Field(default_factory=lambda: int(time.time())) @app.get("/v1/models", response_model=ModelList) async def list_models(): global model_args model_card = ModelCard(id="gpt-3.5-turbo") return ModelList(data=[model_card]) @app.post("/v1/chat/completions", response_model=ChatCompletionResponse) async def create_chat_completion(request: ChatCompletionRequest): global model, tokenizer if request.messages[-1].role != "user": raise HTTPException(status_code=400, detail="Invalid request") query = request.messages[-1].content prev_messages = request.messages[:-1] if len(prev_messages) > 0 and prev_messages[0].role == "system": query = prev_messages.pop(0).content + query history = [] if len(prev_messages) % 2 == 0: for i in range(0, len(prev_messages), 2): if prev_messages[i].role == "user" and prev_messages[i+1].role == "assistant": history.append([prev_messages[i].content, prev_messages[i+1].content]) if request.stream: generate = predict(query, history, request.model) return EventSourceResponse(generate, media_type="text/event-stream") response, _ = model.chat(tokenizer, query, history=history) choice_data = ChatCompletionResponseChoice( index=0, message=ChatMessage(role="assistant", content=response), finish_reason="stop" ) return ChatCompletionResponse(model=request.model, choices=[choice_data], object="chat.completion") async def predict(query: str, history: List[List[str]], model_id: str): global model, tokenizer choice_data = ChatCompletionResponseStreamChoice( index=0, delta=DeltaMessage(role="assistant"), finish_reason=None ) chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk") #yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False)) yield "{}".format(chunk.model_dump_json(exclude_unset=True)) current_length = 0 for new_response, _ in model.stream_chat(tokenizer, query, history): if len(new_response) == current_length: continue new_text = new_response[current_length:] current_length = len(new_response) choice_data = ChatCompletionResponseStreamChoice( index=0, delta=DeltaMessage(content=new_text), finish_reason=None ) chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk") #yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False)) yield "{}".format(chunk.model_dump_json(exclude_unset=True)) choice_data = ChatCompletionResponseStreamChoice( index=0, delta=DeltaMessage(), finish_reason="stop" ) chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk") #yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False)) yield "{}".format(chunk.model_dump_json(exclude_unset=True)) yield '[DONE]' if __name__ == "__main__": tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True) model = AutoModel.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True).cuda() # 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量 # from utils import load_model_on_gpus # model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2) model.eval() uvicorn.run(app, host='0.0.0.0', port=8000, workers=1) - 服务端开启服务:
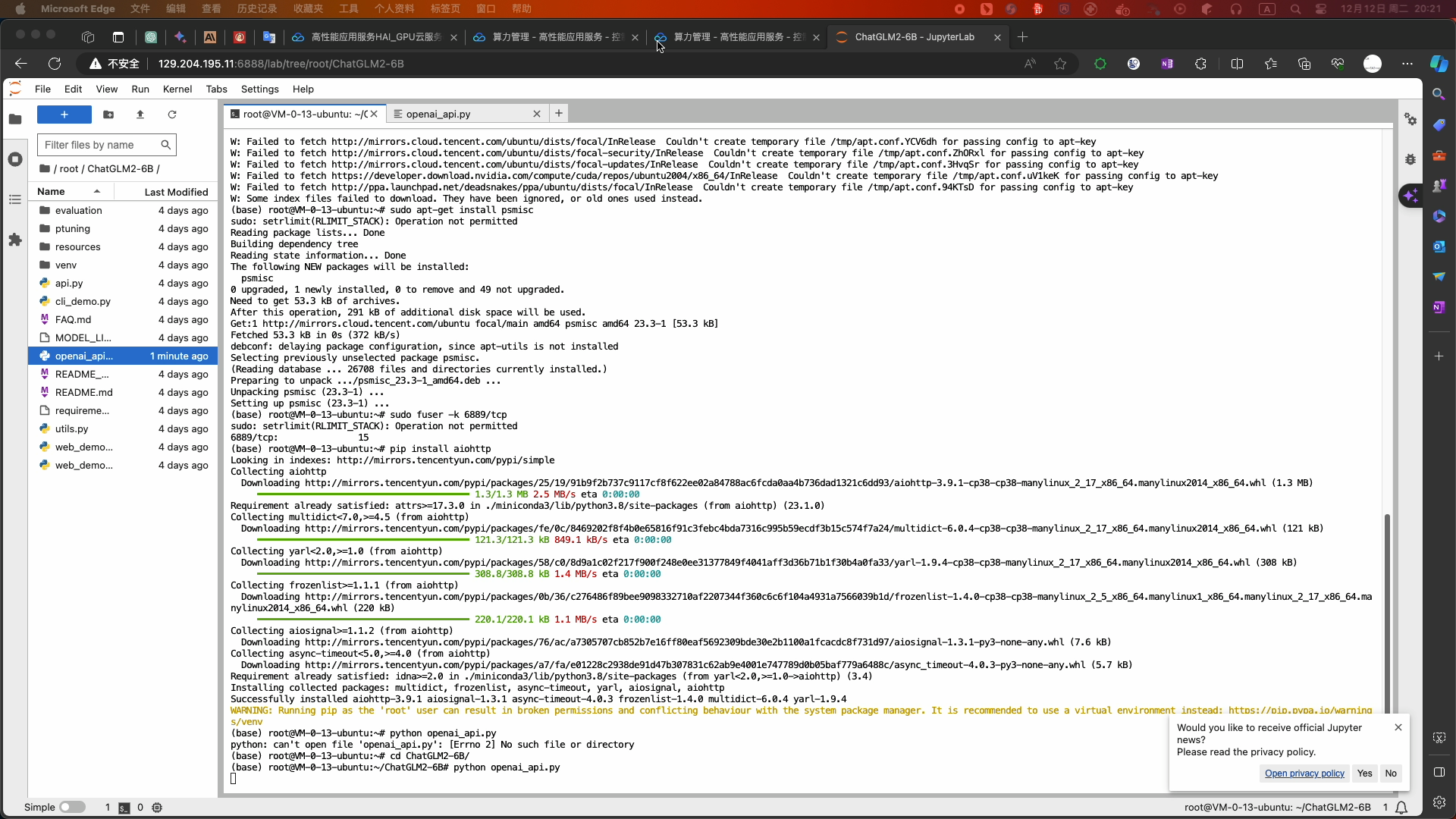
-
python openai_api.py - 使用Cloud Studio快速创建
- 应用推荐下的ChatGPT Next Web开源项目
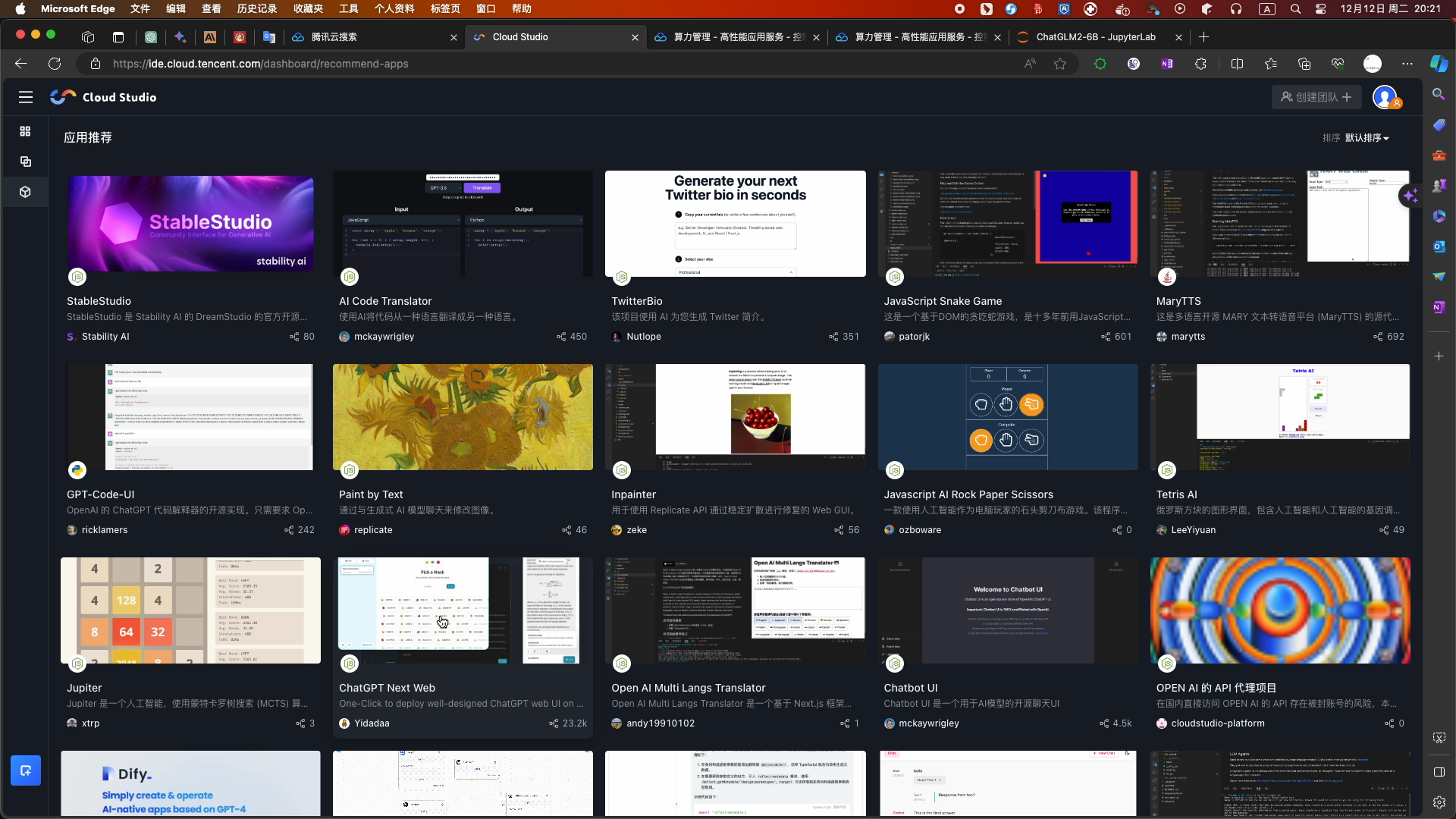
- 选择Fork
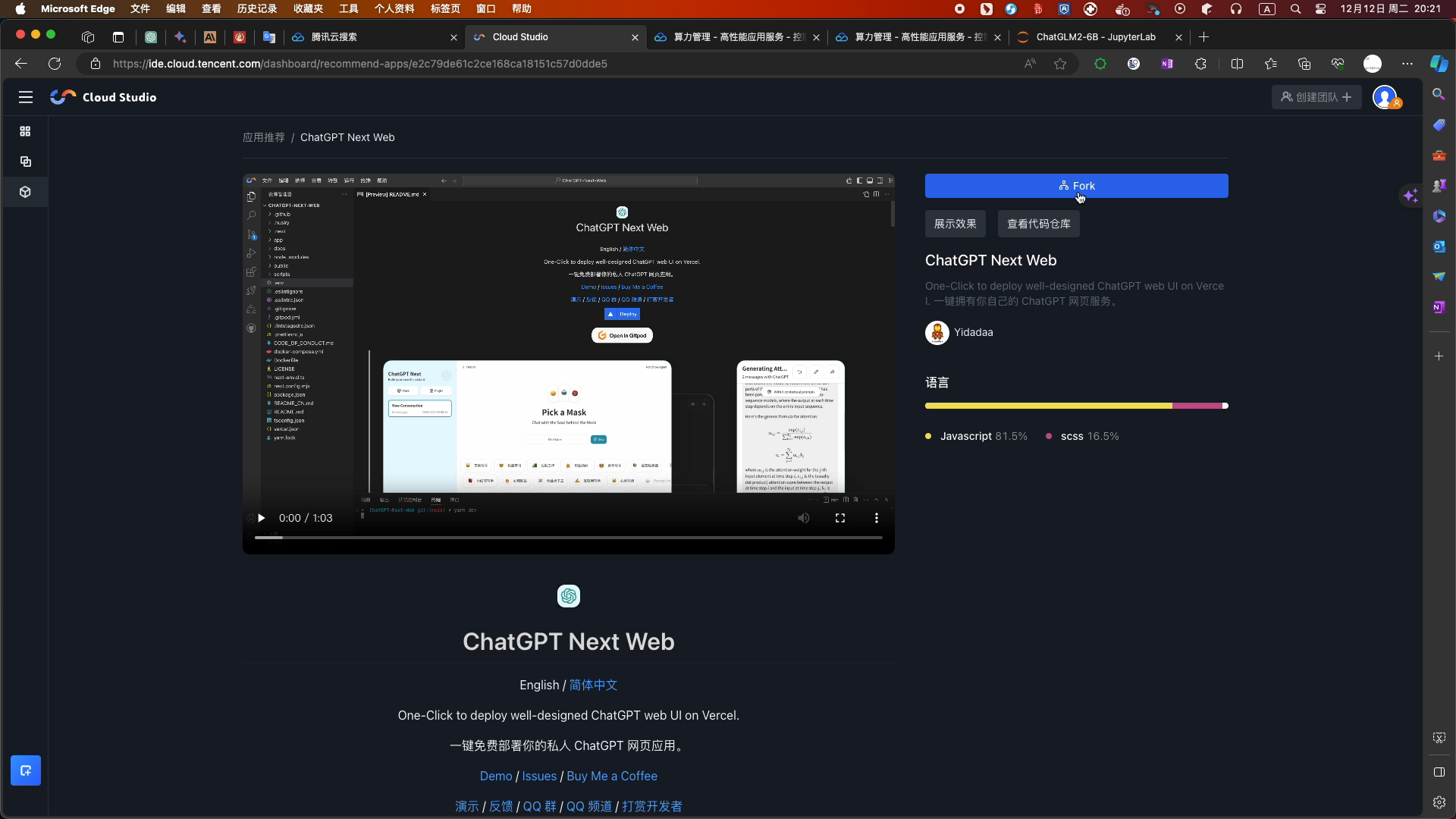
- 等待数秒后,工作空间创建完毕
- Fork完成后,选择.env.template文件
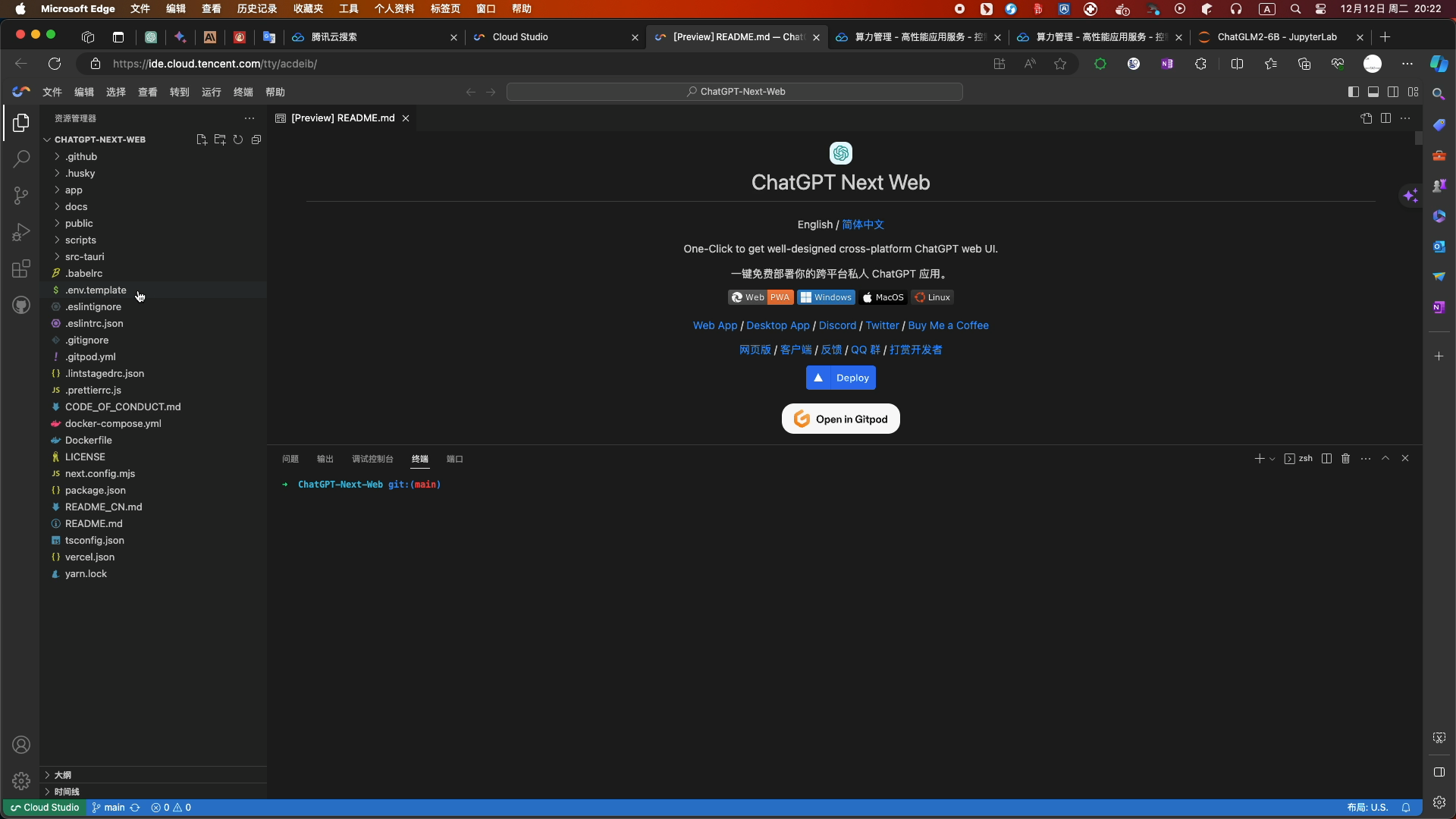
- 修改配置信息如下:
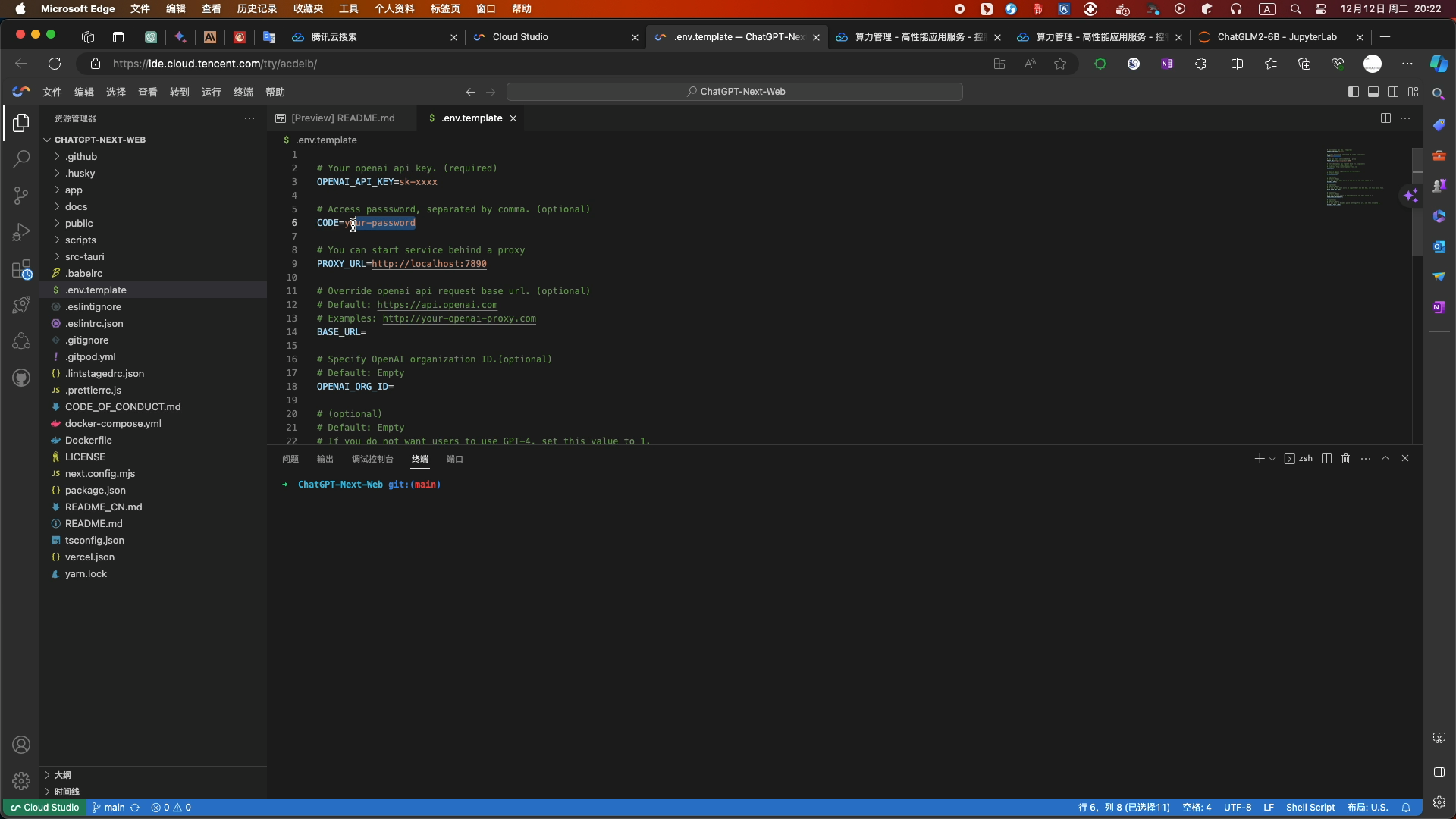
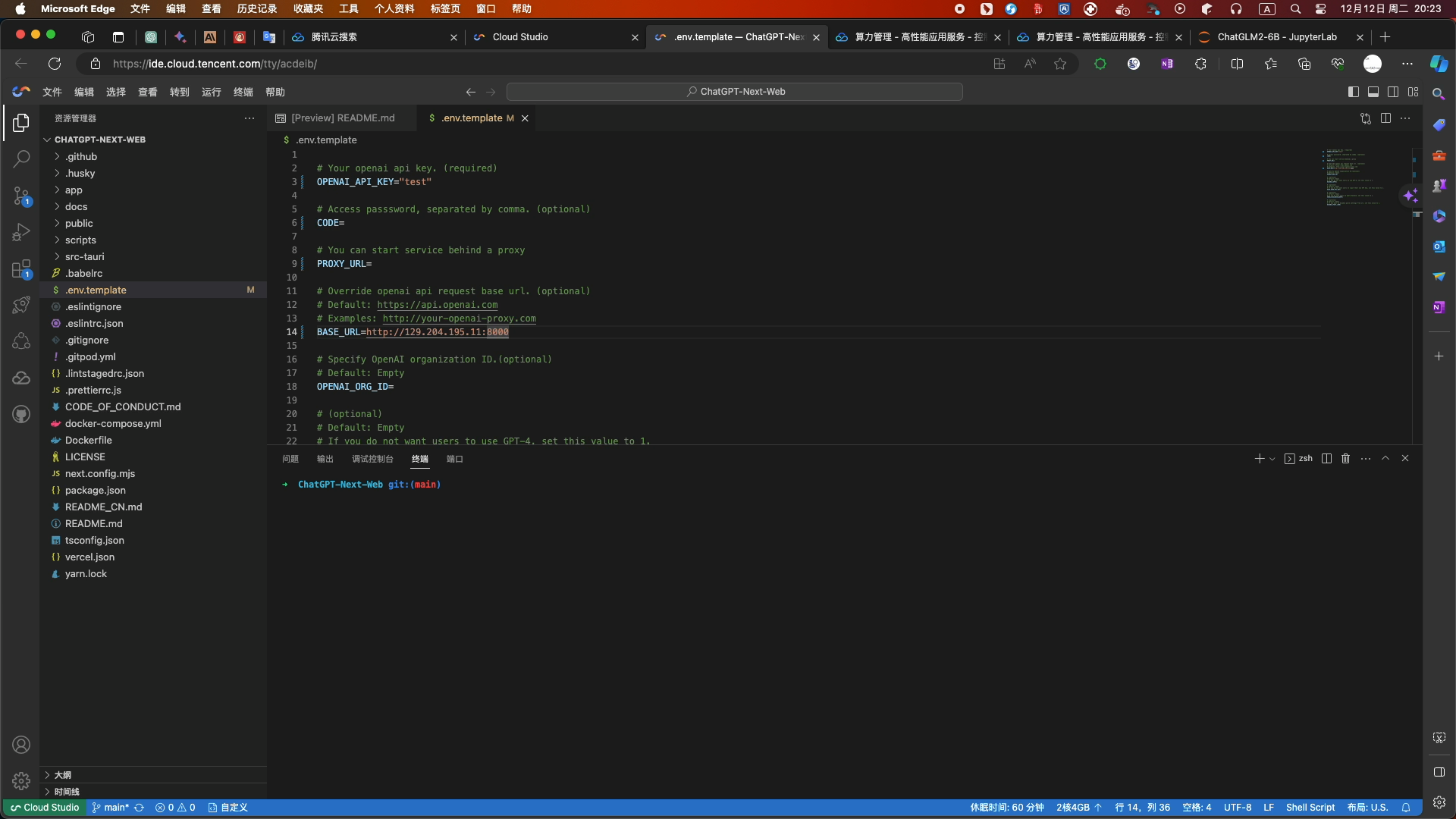
- CODE为空 PROXY_URL和BASE_URL为你的服务器地址和端口
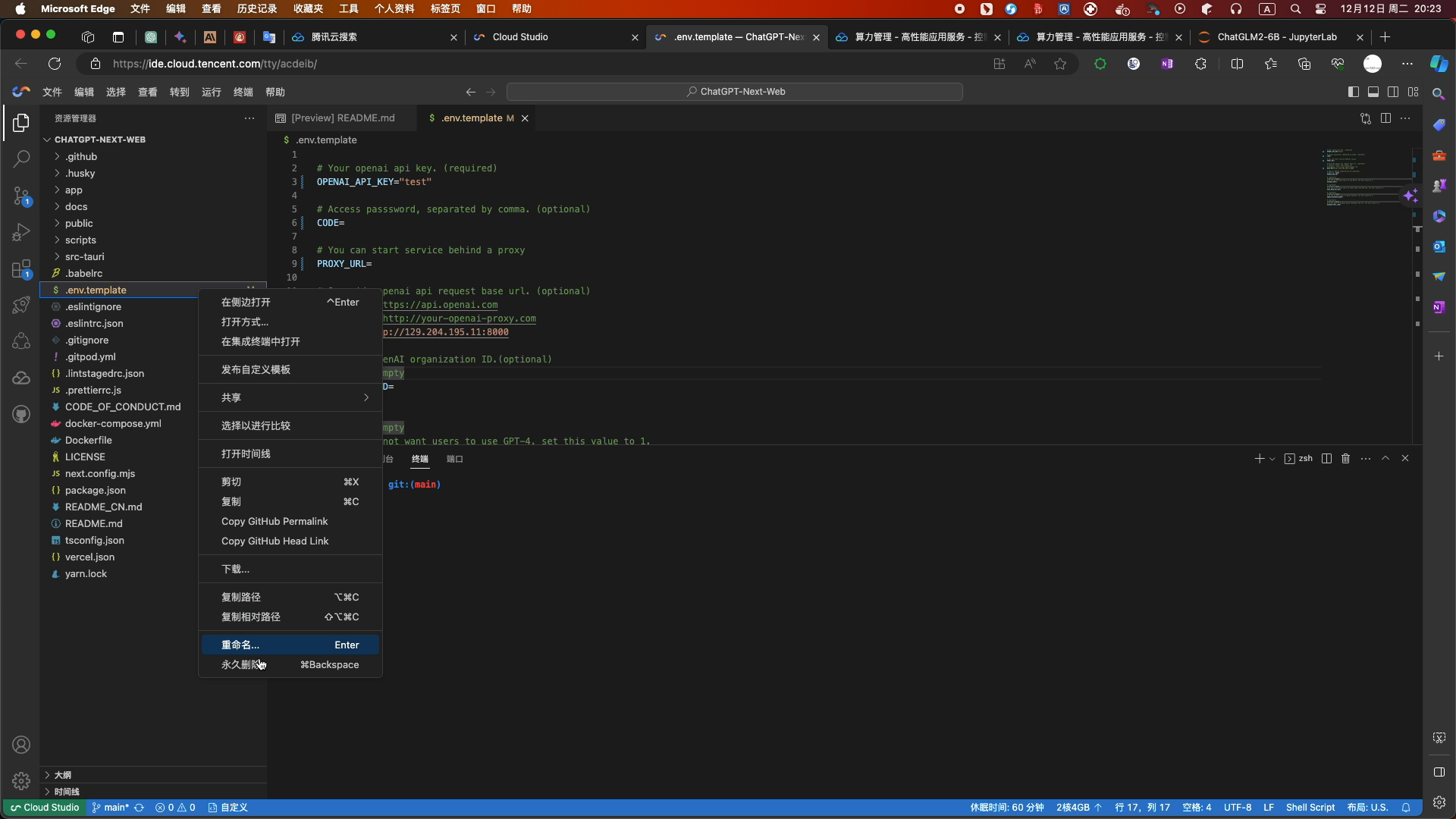
- 修改文件后缀名为.env
- 安装依赖
-
npm install - 依赖安装完成后,输入命令开启服务
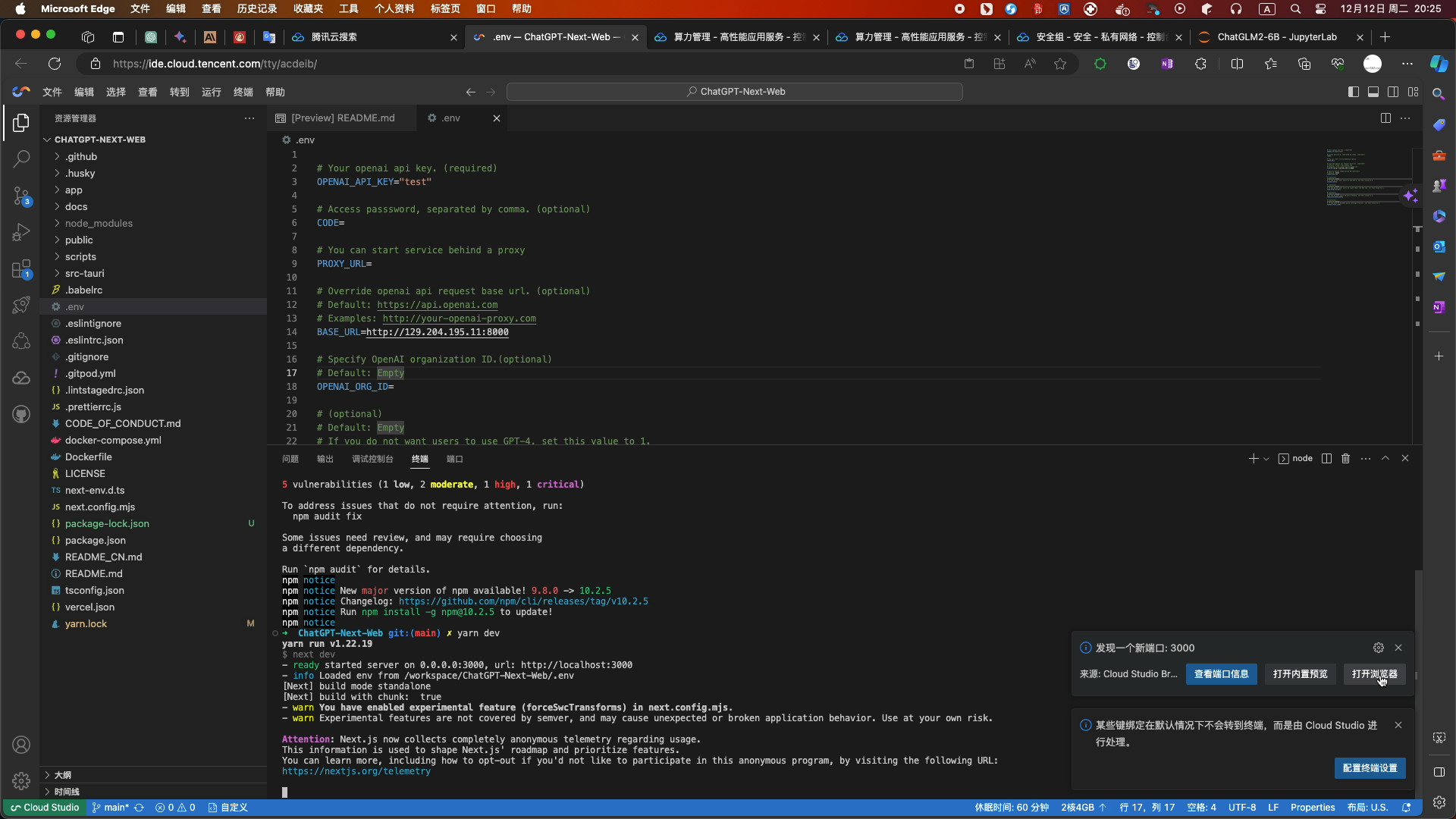
-
yarn run- 点击端口,可使用浏览器或标签页两种方式运行项目
- web浏览器测试:
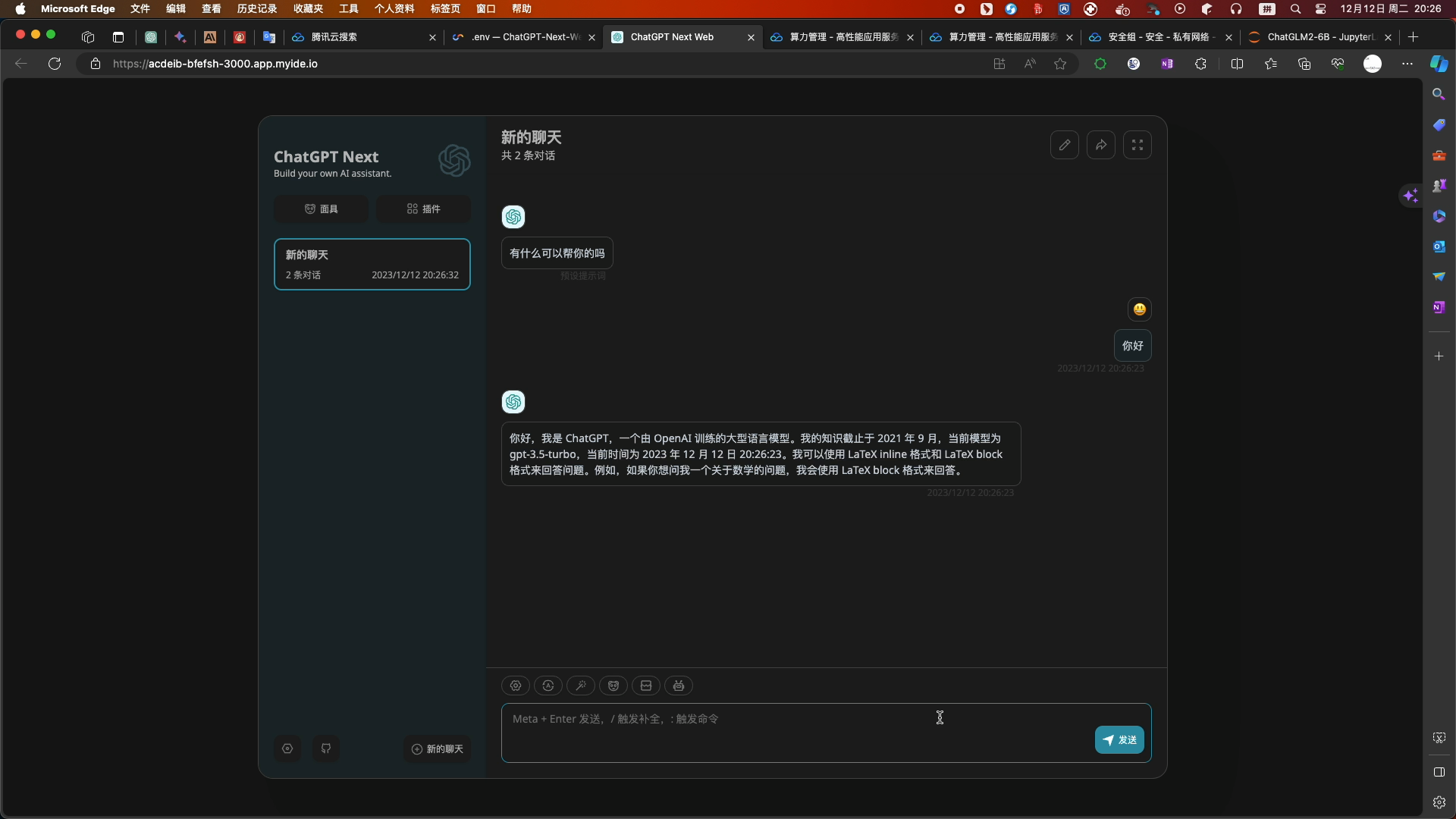
- 服务端可查看相关的请求记录
- 不用了记得及时停止Cloud Studio工作空间服务和关闭HAI服务!
全文结束!
快去尝试一下吧,欢迎评论留言!
- 在算力管理页面,选择进入jupyter_lab页面