相关信息
基于游戏目标的模型基准测试
| 组别 | 指标 | GPT-3.5 | GPT-4V | DEPS | Jarvis-1 | Optimus-1 | 人类水平 |
|---|---|---|---|---|---|---|---|
| 木材 | 成功率(SR) ↑ | 40.16 | 41.42 | 77.01 | 93.76 | 98.60 | 100.00 |
| 平均时间(AT) ↓ | 56.39 | 55.15 | 85.53 | 67.76 | 47.09 | 31.08 | |
| 平均分数(AS) ↓ | 1127.78 | 1103.04 | 1710.61 | 1355.25 | 841.94 | 621.59 | |
| 石头 | 成功率(SR) ↑ | 20.40 | 20.89 | 48.52 | 89.20 | 92.35 | 100.00 |
| 平均时间(AT) ↓ | 135.71 | 132.77 | 138.71 | 141.50 | 129.94 | 80.85 | |
| 平均分数(AS) ↓ | 2714.21 | 2655.47 | 2574.30 | 2830.50 | 2518.88 | 1617.00 | |
| 铁 | 成功率(SR) ↑ | 0.00 | 0.00 | 16.37 | 36.15 | 46.69 | 86.00 |
| 平均时间(AT) ↓ | ∞ | ∞ | 944.61 | 722.78 | 651.33 | 434.38 | |
| 平均分数(AS) ↓ | ∞ | ∞ | 8892.24 | 8455.51 | 6017.85 | 5687.60 | |
| 黄金 | 成功率(SR) ↑ | 0.00 | 0.00 | 0.00 | 7.20 | 8.51 | 17.31 |
| 平均时间(AT) ↓ | ∞ | ∞ | ∞ | 787.37 | 726.35 | 557.08 | |
| 平均分数(AS) ↓ | ∞ | ∞ | ∞ | 15747.13 | 15527.07 | 13141.60 | |
| 钻石 | 成功率(SR) ↑ | 0.00 | 0.00 | 0.60 | 8.98 | 11.61 | 16.98 |
| 平均时间(AT) ↓ | ∞ | ∞ | 1296.96 | 1255.06 | 1150.98 | 744.82 | |
| 平均分数(AS) ↓ | ∞ | ∞ | 23939.30 | 25101.25 | 23019.64 | 16237.54 | |
| 红石 | 成功率(SR) ↑ | 0.00 | 0.00 | 0.00 | 16.31 | 25.02 | 33.27 |
| 平均时间(AT) ↓ | ∞ | ∞ | ∞ | 1070.42 | 932.50 | 619.89 | |
| 平均分数(AS) ↓ | ∞ | ∞ | ∞ | 17408.40 | 12709.99 | 12357.00 | |
| 盔甲 | 成功率(SR) ↑ | 0.00 | 0.00 | 9.98 | 15.82 | 19.47 | 28.48 |
| 平均时间(AT) ↓ | ∞ | ∞ | 997.59 | 924.60 | 824.53 | 634.28 | |
| 平均分数(AS) ↓ | ∞ | ∞ | 17951.95 | 16492.96 | 16350.56 | 11026.00 | |
| 综合表现 | 成功率(SR) ↑ | 0.00 | 0.00 | 5.39 | 16.89 | 22.26 | 36.41 |
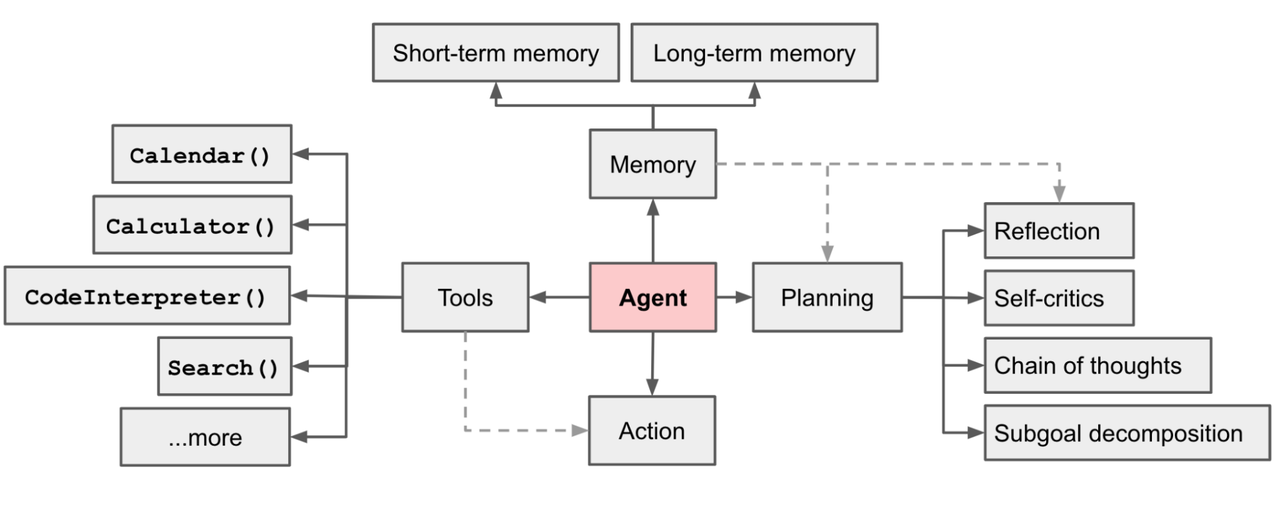
主要框架
长期记忆
- 混合多模态记忆,由知识和经验组成
规划器
- 基于知识指导的规划器
反思器
- 经验驱动的反思器
行为控制器
混合多模态记忆
认知理论
长期记忆系统包括情景记忆与语义记忆
| 维度 | 语义记忆系统 | 情景记忆系统 |
|---|---|---|
| 内容 | 存储一般事实、概念、常识和语言知识 | 存储个人经历、特定事件及其背景 |
| 时间与地点 | 不依赖于特定的时间和地点,抽象的知识 | 强调特定的时间、地点和个人情境 |
| 个性化 | 内容不具个性化,适用于所有人(普遍性知识) | 强烈个性化,基于个体的生活经验和情感体验 |
| 例子 | “蜜蜂是飞行昆虫,产生蜂蜜。” | “上周末在公园野餐时,我被蜜蜂叮咬了。” |
| 作用 | 提供对世界的普遍理解和知识 | 记录和重现个体的特定事件和生活经历 |
组件
- 知识:分层有向知识图谱(HDKG:Hierarchical Directed Knowledge Graph)
- 存放世界知识
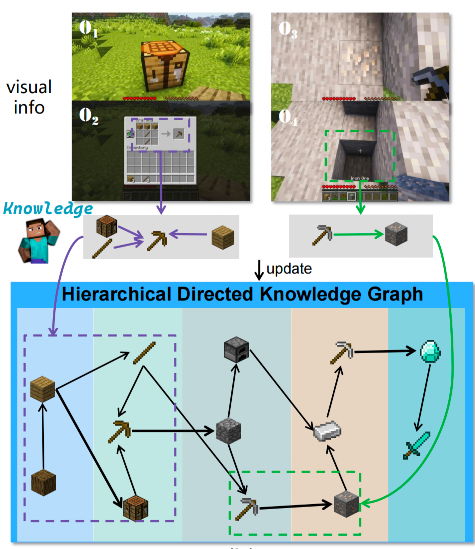
- 存放世界知识
- 经验:抽象多模态经验库(AMEP:Abstracted Multimodal Experience Pool)
- 存放任务成功和失败的历史
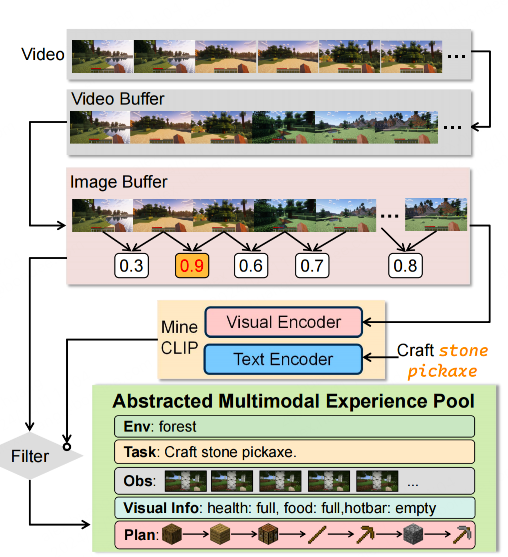
- 通过总结来压缩存储空间并提高检索效率
基于知识指导的规划器
从HDKG中获取必需的知识 结合当前状态的视觉观察
经验驱动的反思器
定期启动从经验池获取多模态经验 结合当前状态的视觉观察 反思当前的行动,返回:继续、已完成或重新规划
行为控制器
输入
- 存放任务成功和失败的历史
- 当前的观察
- 当前的子目标
输出
- 驱动行为的控制信号
自主学习
- 自由探索
- 教师指导
评估策略
- 每次运行时清空角色携带物品,并将其放置于随机地点
- 只基于键盘和鼠标进行操作
案例


